NEW!
Introducing: Optimize, by MindCache
Speed up development with tools to understand, debug, and improve workflows, without the guesswork.
PCA+tSNE/UMAP clustering integrated with available metadata
Remove outliers manually, or generate filters to exclude them from future imports
Quickly review newly ingested data and its relationship to existing data
Visualize embeddings in 2d space
Easily query vector databases to understand top_k and score thresholds
Quickly diagnose parser and chunking issues on unstructured data
Overview
To implement a successful Retrieval-Augmented Generation (RAG) solution, having well designed embeddings is essential. However, creating chunked embeddings from unstructured documents, such as HTML, can be a complex task.
Poorly formatted Web pages, PDFs and other document types often break common parsers, resulting in chunked embeddings full of junk data. As the size of your vector database increases and new documents are added, so are new unstructured data errors.
To help diagnose these issues, we are introducing the first in a suite of developer tools, Optimize, by MindCache.
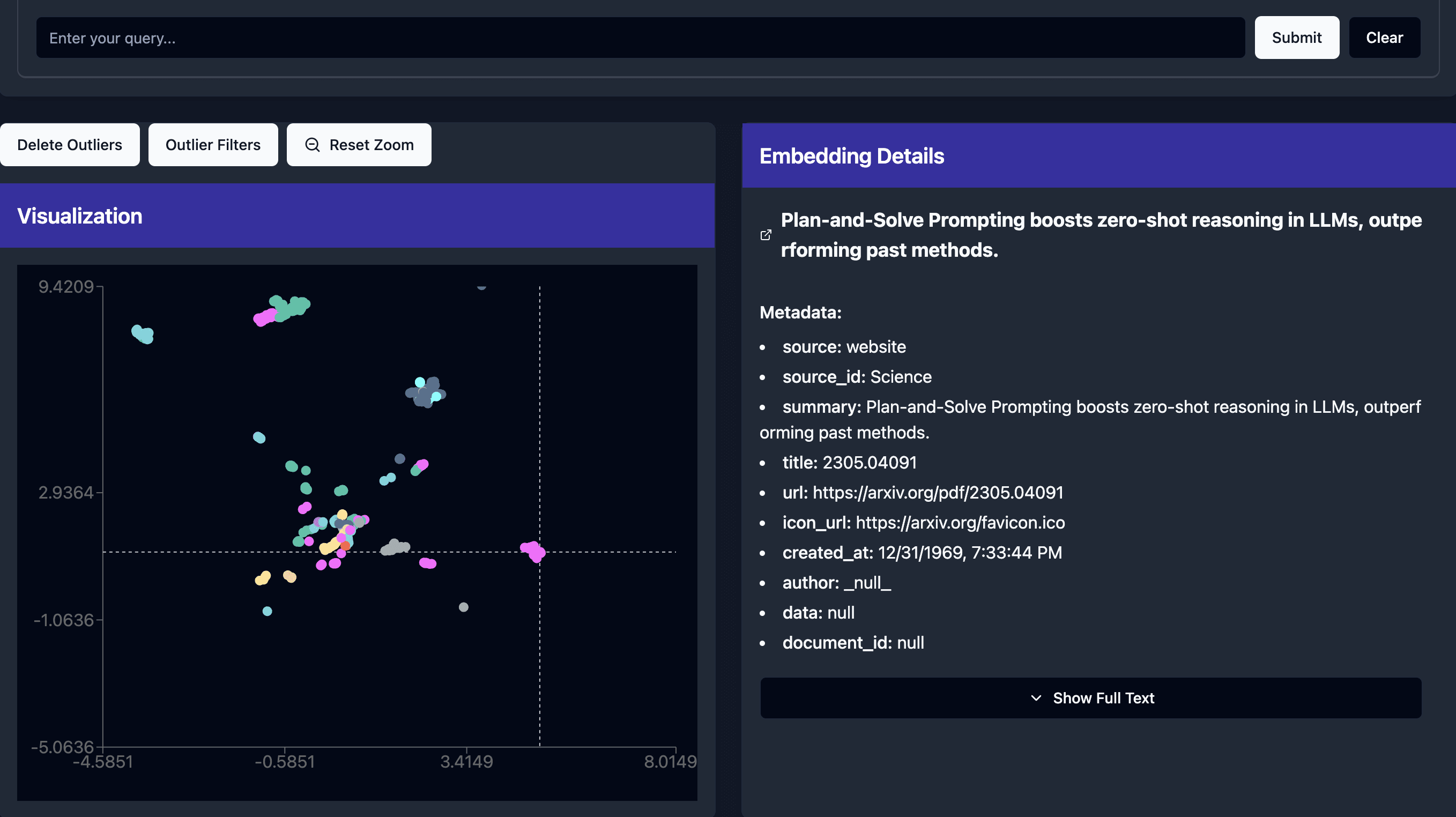
Embedding Visualization
Visualize embeddings using PCA + UMAP or tSNE dimension reduction. Use the resulting clusters to gain insights into embeddings and their metadata.
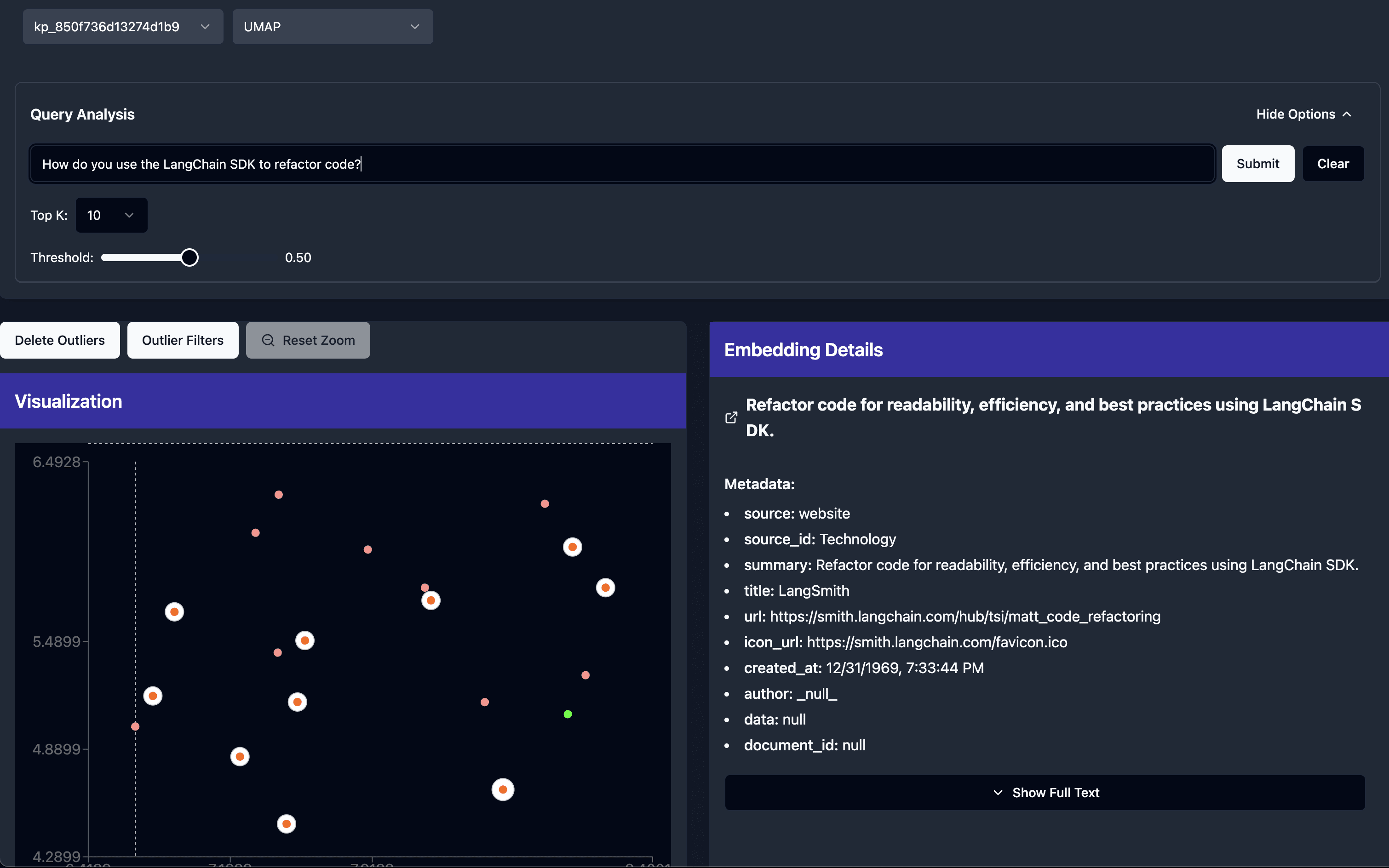
Query and Review
Run live queries against the dataset to quickly review the top_n chunks and optimize context usage.
Outlier Removal
Unstructured documents can complicate document embeddings. Poorly structured text can break parsers, creating chunks of useless text that can impact query performance.
MindCache provides multiple visualization techniques to quickly find clusters, inspect metadata, and act on the results.
Integrating MindCache into your development processes, developers can find parser problems during development. Later, QA can file bad embeddings and clusters as bugs during testing, and production issues can be quickly traced back to their source.
Bad chunks can either be deleted directly from the datastore, or filters can be generated to remove them as they appear.
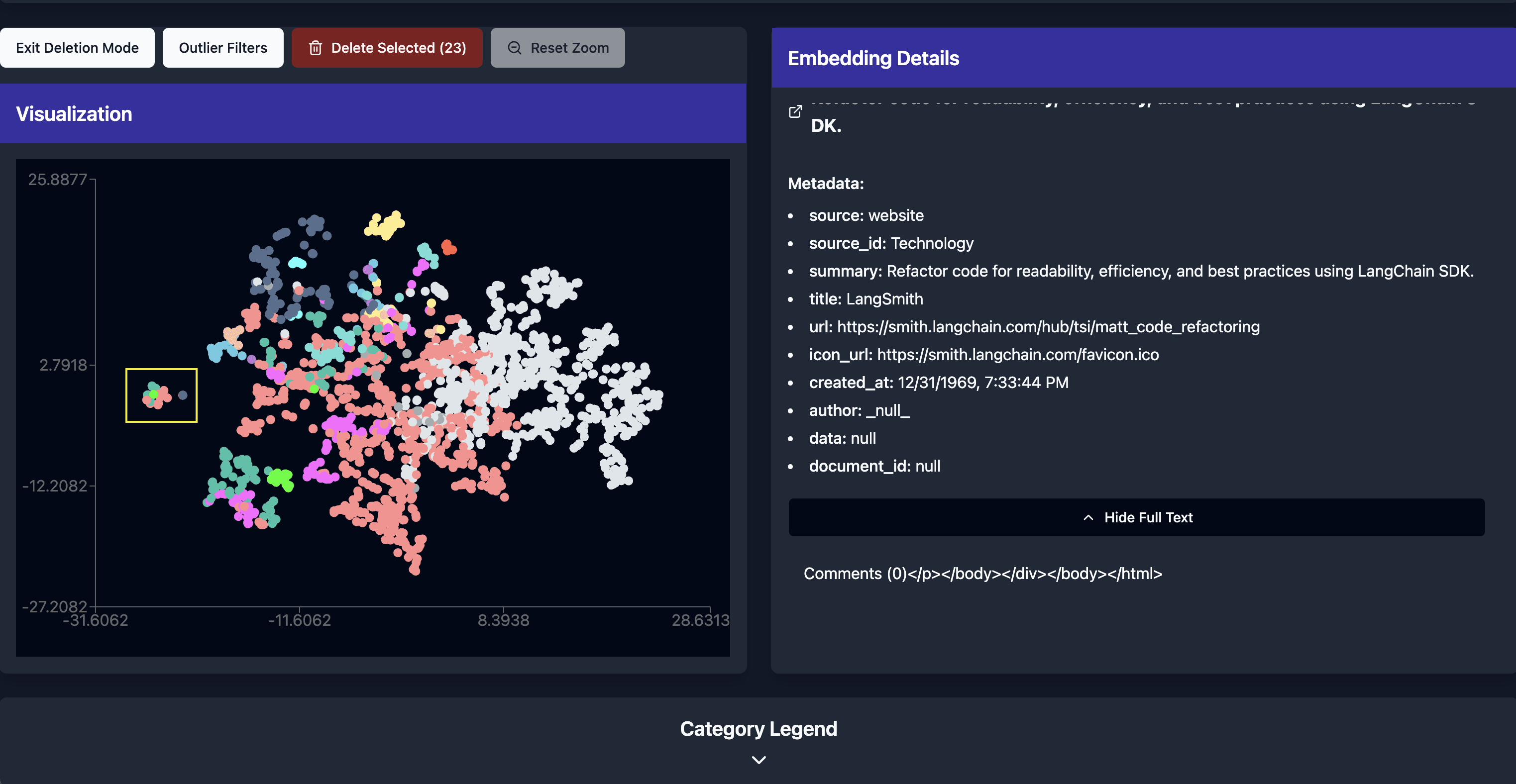
Recommended Filters
In many cases, post-processing is the most straightforward solution to remove unwanted embeddings. Highlight a selection of similar embeddings to generate a filter, removing all matching chunks from future queries.
MindCache.io
Contact
info@mindcache.io
© 2024 MindCache.io - All rights reserved